JVC DIGITAL S - VIDEO COMPRESSION PROCESSING AND RECORDING
|
Yoshimichi Nagaoka |
Kiyoshi Honma |
David Gifford |
Neil Neubert |
|
Victor Co. of Japan |
Victor Co. of Japan |
Victor Co. of Japan |
JVC Professional Products Company |
Introduction
The Digital S video tape recording format combines a unique dual digital video compression processing system with a one half inch video tape transport adapted and highly upgraded from the S-VHS video tape transport. The upgraded transport provides rugged and reliable service used with metal particle video tape and running at higher tape and drum rotation speeds. The processing and transport combination yields a high performance but low cost digital video tape recording system.
A Digital S compressed digital video interface has been developed to permit the connection of Digital S signals between VCR’s and other video equipment without the need to decode and encode between non-compressed digital video formats (ITU-R BT.601).
The technologies employed in Digital S compression and processing, the Digital S video tape and tape track characteristics, and the Digital S interface are described in the following sections.
Digital S Video Tape Tracks
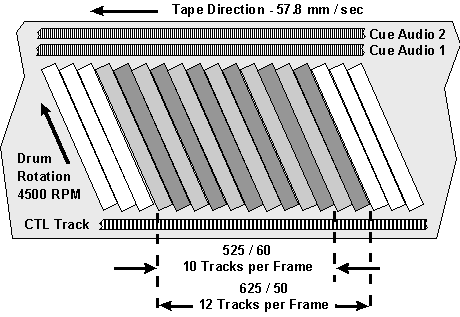
Digital S employs a two-track, parallel recording system with a pair of heads located on each side of the drum, and aligned exactly opposite each other (180°). A single frame of video is recorded on 10 tracks (5 track pairs) for 525/60, and 12 tracks (6 track pairs) for 625/50 television systems.
VIDEO TAPE TRACKS - 525/60 AND 625/50
The detailed Digital S videotape track pattern is shown in the figure below. The compressed digital video data, non-compressed digital audio data, and subcode (including system data) are written on individual sectors along the helical tracks by the rotating heads. Guard band gaps are provided between all of the sectors to permit independent editing of each sector.
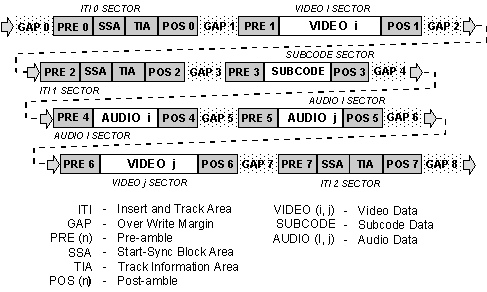
DIGITAL S HELICAL VIDEO TAPE TRACK SECTORS
Digital S employs ½ inch metal particle video tape housed in a video cassette that is very similar to an S-VHS video cassette. The Digital S tape transport is an upgrade and adaptation the of S-VHS tape transport. Adaptation of the video cassette and tape transport for Digital S results in economy, time proven quality and reliability, and playback compatibility for analog S-VHS video tapes. Certain Digital S players will accept and play back S-VHS, as well as Digital S video tapes. Tape, cassette and transport similarities make interesting, a comparison of Digital S and S-VHS tape track characteristics. These are illustrated in the table below.
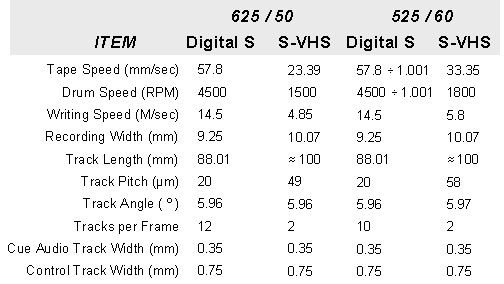
DIGITAL S / S-VHS TRACK COMPARISON TABLE
Digital S Video Tape
Digital S uses modern, high performance dual coat metal particle video tape. The tape applies ultra-fine metal particles for reliable, high output, low error, high density recording. Some specifications for the video tape are included in the table below.
|
Tape Width: |
12.65 mm |
|
Tape Width Variation: |
2.0 µm (PP) |
|
Tape Thickness: |
14.4 µm |
|
Coercivity: |
» 1830 Au |
|
Coercive Force: |
145.1 KA/m |
|
Maximum Residual Flux Density: |
310 mT |
|
Flux Density Br: |
3000 Gauss |
|
Minimum Wavelength: |
0.488 µm |
The Digital S video cassette is very similar to an S-VHS video cassette. It uses a high precision cassette shell, static electricity free lid, and a shield that prevents entry of dust while the cassette is not in use. Maximum recording time with 14.4 µm thick tape is 104 minutes.
Digital S Bandwidth Compression
The data transmission rate of a component digital video signal, encoded in compliance with ITU-R BT.601 and not compressed, is approximately 166 Mb/s. Recording this data rate generally results in high equipment and media cost, and short recording time. Bit rate reduction, or compression of the ITU-R BT.601 signals can serve to reduce the cost of equipment and media and lengthen recording time. The application of bit rate reduction requires a balance between the reduced transmission rate, and the
compression errors that result. This balance was determined for the Digital S compression system by simulating the relationship between transmission data rate and compression related errors.
The figure below illustrates the result of the simulation. The horizontal axis shows transmission rate. The vertical axis shows the average error for one pixel of the compressed picture at a starting point with an error of 1.0, at a rate of 30 Mb/s. Three grades of images, including an MPEG estimation chart, were used. As the transmission rate is increased, that is, the picture is compressed less, the error became less, accordingly. At a point on the transmission rate axis, the error is significantly improved, and the rate of improvement becomes much less as the transmission rate continues to increase. That transmission rate point is about 50 Mb/s for the Digital S compression system. Thus 50 Mb/s was determined to be the ideal balance between transmission rate and error, and chosen for Digital S.
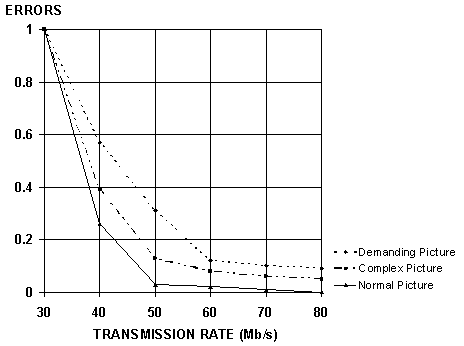
TRANSMISSION BIT RATE VERSUS ERROR
Digital S Video Parameters
Digital S uses the 4:2:2 image sampling structure specified by Recommendation ITU-R BT.601. Digital S sampling, line structure, and quantization scales are shown in the tables below.

DIGITAL S SAMPLING AND LINE STRUCTURE

DIGITAL S QUANTIZATION SCALE AND LEVELS
Television distribution services are rapidly migrating to digital delivery to the home receiver using MPEG-2 compressed digital video. The choice of ITU-R BT.601 compliant, 4:2:2 sampling for Digital S assures satisfactory concatenation to the 4:2:0 sampling structure of the MPEG-2 ML @ MP used for digital television distribution. The following figure shows these two image sampling structures.
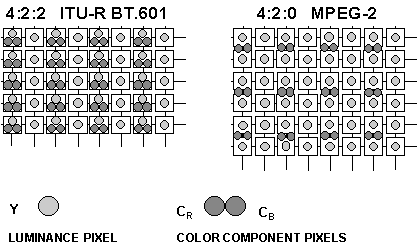
COMMON IMAGE SAMPLING STRUCTURES
Digital S Processing
Digital S applies dual compression sections in a form of parallel compression processing to simultaneously encode (compress) equal halves of the input signal. A block diagram illustrating one example of Digital S encoding is shown below.
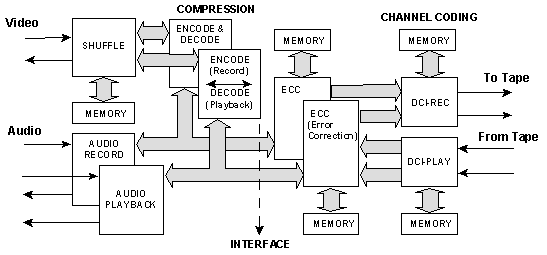
DIGITAL S - POSSIBLE IMPLEMENTATION
Digital S utilizes the DCT (Discrete Cosine Transform) process to transform an 8H × 8V pixel arrangement to an 8 × 8 matrix of DCT coefficients. DCT blocks of an 8 × 8 dimension are used for luminance (Y), and each color component, R–Y, and B–Y. Digital S DCT blocks are combined to form macro blocks. One Digital S macro block is made up of four DCT blocks; two luminance (Y) DCT blocks, and one each DCT block for the (R-Y) and (B–Y) color components. One macro block is the basic element of the error concealment process in Digital S. Macro blocks are combined to form super blocks. Twenty seven adjacent macro blocks, 9 Horizontal × 3 Vertical macro blocks, form a single super block. Digital S DCT, macro and super blocks are illustrated in the drawing below.
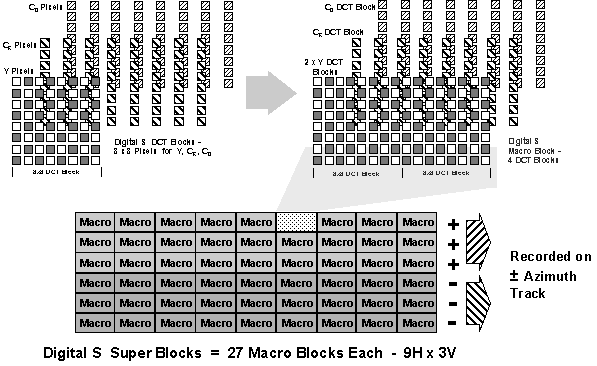
DIGITAL S - PIXELS TO DCT BLOCKS TO MACRO BLOCKS TO SUPER BLOCKS TO TAPE TRACKS
Super blocks are arranged in the video frame so linear sequences of them, representing coherent and continuous horizontal rows in the video frame, can be recorded on the video tape tracks to permit good visible picture display in shuttle, search, and slow motion playback modes. Digital S provides good picture display at search speeds up to 32 times normal playback speed in forward and reverse, and high quality digital slow motion playback between ± 1/3 times normal playback speed.
Digital S writes six track pairs to record a 625/50 video frame on tape. Track pairs are written by two head pairs, located 180 degrees apart on the head drum. The heads in each pair are of opposite azimuth angles. The first track of a pair possesses a positive azimuth angle, and the second, a negative azimuth angle. Super blocks representing the same portion of every video frame would, therefore, be recorded on, and played back from the same tracks, by the same head pairs, for every video frame since there are two head pairs, and six is an even number of track pairs. Consequently, odd and even rows of super blocks are alternately recorded on the first (positive) and second (negative) azimuth tracks of succeeding frames so that the played back picture may be renewed every two frames in the event of the failure of a single record or playback head.
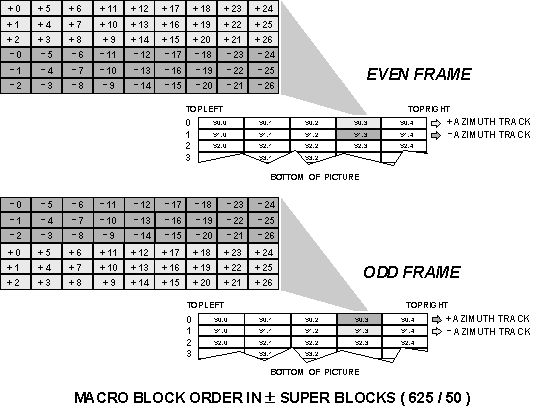
Five track pairs, an odd number, are written by the same two head pairs, an even number, for 525/60 systems. Thus, each track is recorded and played back by the opposite head pair for each succeeding video frame, and alternate odd-even super block recording is not required.
Digital S Shuffling
Prior to encoding (compression), Digital S "shuffles" the digital data representing a video frame for the purpose of distributing complex picture data over the entire video frame. Complex picture information characteristically accumulates in just a few distinct areas of a typical television picture. Shuffling disassembles each video frame in units of one macro block, thereby redistributing adjacent macro blocks evenly over the entire video frame. Areas of concentrated picture complexity are, thus, distributed in small macro block units throughout the stream of digital video data. The compression process does not receive excessive data during very short periods and, consequently, compression performance is significantly improved.
Digital S creates a sequential stream of digital video data "segments" as input to the compression process. A segment is made up of five macro blocks that have been selected from all over the video frame by the shuffling process. Shuffling strives to assure that the amount of data contained in all of the video segments is as equal as possible. The assembly of "shuffled" macro blocks into video segments for input to the encoder is illustrated below.
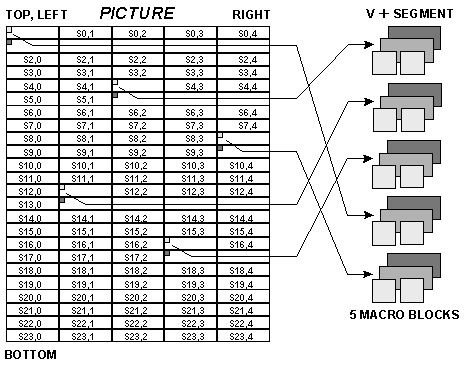
DIGITAL S SHUFFLE PATTERN
Digital S Compressed Video Segment
The Digital S dual compression system can process macro blocks containing six DCT blocks, four luminance (Y), and two color component (R-Y) and (B-Y) in each of the parallel compression processes. Digital S macro blocks, however, contain four DCT blocks, possessing only two, instead of the four, luminance (Y) DCT blocks that can be processed. Digital S adds two new DCT blocks to each of its macro blocks so that six DCT blocks are contained in the macro block that is to be processed.
AC coefficient data samples for each DCT block are stored in the areas reserved for them within their associated DCT blocks. AC coefficient data that exceeds the storage capacity of its DCT block, can be stored in vacant AC coefficient capacity in other DCT blocks within the same macro block, or even within the same video segment. The two new DCT blocks that Digital S adds to each of its macro blocks prior to processing, are used to supply additional AC coefficient data storage capacity, thus, permitting more high frequency luminance and color components of the image to be recorded. The capacity of the additional new DCT blocks can be used to store excess AC coefficient data from any of the original four DCT blocks in the same macro block, and, excess data from other DCT blocks contained in the same video segment. The following illustration shows the added DCT blocks and how five video segments are combined to form one compressed video segment.
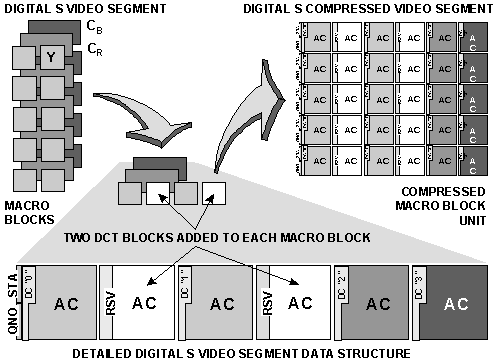
DETAILED DIGITAL S VIDEO SEGMENT DATA STRUCTURE
Digital S Compression Processing
Digital S employs conventional DCT transformation of the time based digital video data to a stream of frequency based DCT coefficients. DCT coefficient weighting is applied before further processing and the weighting characteristic for the 8 × 8 matrix is shown in the figure below.
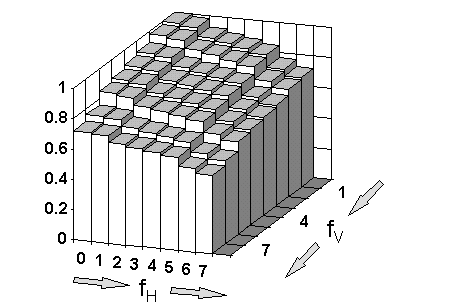
DIGITAL S DCT COEFFICIENT WEIGHTING
Initial scaling transforms the AC coefficients from 10 to 9 bits by rounding them off. DCT blocks are classified into one of four groups determined by the maximum absolute value of the AC coefficients each contains. A simple 8 × 8 pixel DCT block, containing little information that is difficult to compress, might have only a few AC coefficients of low value. Such DCT block might, therefore, be a Class 0 DCT block. A DCT block containing complex picture information might have many AC coefficients of moderate value, or even, a few AC coefficients of high value. Such DCT blocks might, therefore, be Class 3 DCT blocks. Class 3 is scaled more precisely than classes 0, 1 and 2.
Estimation is a process of selecting the quantization factor to be applied to each Digital S video segment (5 macro block sequence). Output data cannot exceed a maximum size of 385 bytes for each video segment. The quantization factor is chosen by a process of estimating the output data from the DCT AC coefficient data present at the quantizer input for each video segment. Factors are chosen to achieve the least compression and, therefore, the best possible picture quality within the output limit of 385 bytes.
The applied quantization factor, that is, an actual number that the DCT AC coefficient data is divided by in the quantizer, is determined by the estimation process. Four defined frequency dependent areas of the 8 × 8 DCT blocks can be quantized by different divisors and there are nine possible divisor combinations for these four areas. The divisors are determined by the class number of the DCT data in each video segment and the QNO, or quantization number from 0 to 15, that assures the output data will be 385 bytes or less. One figure below defines the areas of the 8 ´ 8 DCT coefficient matrix. Two other figures below show the nine quantization (QTZ) divisor combinations and the areas within the 8 ´ 8 DCT coefficient matrix to which they are applied.
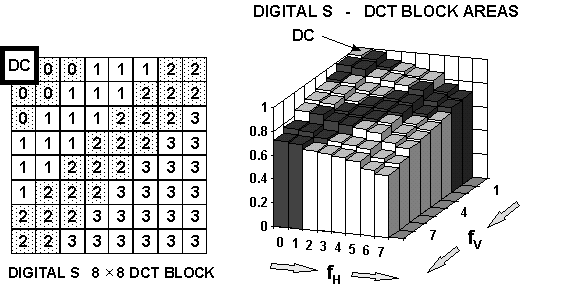
DIGITAL S DCT BLOCK AREAS
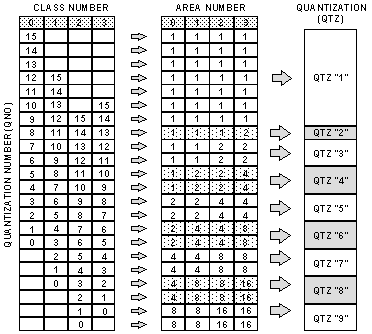
DIGITAL S QUANTIZE (QTZ) TABLES
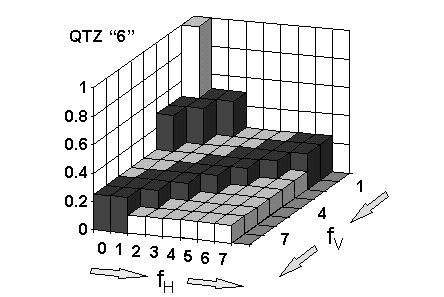
EXAMPLE - QTZ "6" QUANTIZING APPLIED TO DCT BLOCK AREAS
Variable length coding utilizes a two dimensional Huffman code. Code word length is determined by the relationship between the "run", the length of consecutively recurring zeroes, and the "amp", the amplitude of the any data value other than zero that immediately follows a "run" of zeroes in each quantized DCT block.
Digital S Video/Audio Sector
Structure of the video and audio sectors is illustrated in the figures that follow. Digital audio is not compressed in the Digital S system. Sync block structure is the same for video and audio and consists of a sync area of two bytes, ID code of three bytes, data of 77 bytes and inner parity of 8 bytes. Total is 90 bytes. Reed-Solomon code (85, 77) is used for the inner code and is the same for both video and audio. Outer parity is Reed-Solomon (149, 138) for video, and Reed-Solomon (14, 9) for audio.
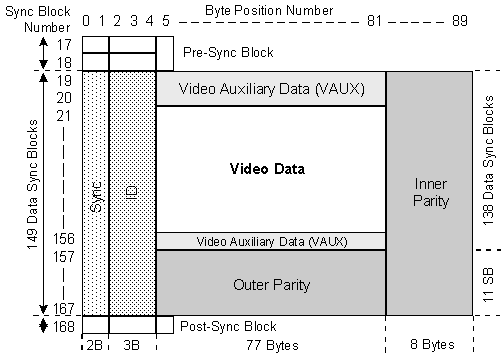
DIGITAL S VIDEO SECTOR
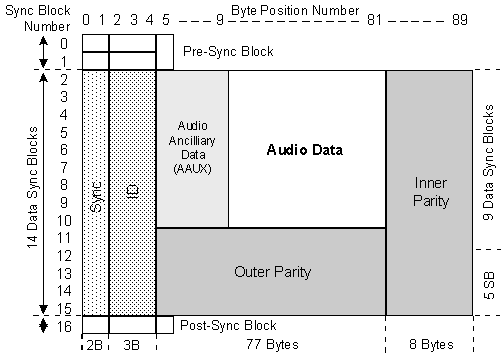
DIGITAL S AUDIO SECTOR
Digital S Modulation
The Digital S modulation scheme employs a combination of randomized bit streams and interleaved NRZI coding. These offer less influence on low frequencies than do NRZI methods that utilize PR4 coding. The modulation process is completed by applying the 24-25 transform. The result is a high performance modulation circuit from less circuitry than that required for other block modulation methods such as 8-14, for instance.
Data is randomized using the M series polynomial function X7+X3+1. 24-25 modulation inserts an extra bit at the beginning of three consecutive randomized bytes resulting in a 25 bit code word. The extra bit can be a "1" or "0" and is chosen to prevent long consecutive sequences of like bits, that is, to maintain the AC characteristic of the modulation signal.
Digital S Interface
Digital S provides a compressed digital data interface bitstream known as the DIF stream. The DIF stream can be used to connect compressed Digital S signals between Digital S VCRs without the need to decode to, and encode from ITU-R BT.601. The DIF bitstream can be mapped to the SMPTE 305M Serial Data Transport Interface (SDTI) and then carried between devices within the data payload of the common SMPTE 259M / ITU-R BT.656 Serial Digital Interface (SDI). The compressed Digital S bitstream thus emerges from the VCR via a conventional SDI signal and can be transported throughout television facilities using their existing infrastructures and standard SDI routing systems. The DIF stream can be mapped to other digital interfaces, as well.
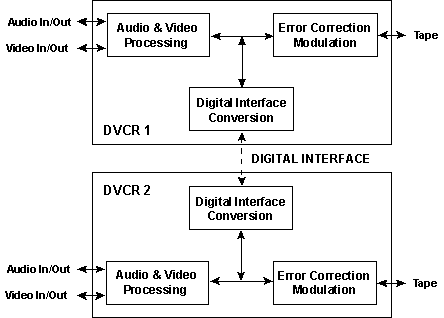
DIGITAL S COMPRESSED DIGITAL VIDEO AND AUDIO (NON-COMRESSED) INTERFACE
The data in one video frame is divided in half to make two "video channels". Ten DIF sequences for 525/60 systems, and twelve DIF sequences for 625/50 systems are contained in one video channel. Each DIF sequence is made up of 150 DIF blocks, each of which contain; header, subcode, V aux, audio, or video data as shown in the following figure. Each DIF block carries 80 bytes of digital data.

TRANSMISSION ORDER OF DIF BLOCKS WITHIN A DIF SEQUENCE
Digital S Summary Specifications

DIGITAL S SPECIFICATION TABLE
The table above provides a summary of the most important Digital S specifications. The Digital-S videotape recording format was designed to satisfy the requirements of many video recording applications. Digital-S possesses exceptional features, performance, and specifications, that will satisfy the video recording needs and requirements of tele-producers, broadcasters, and video professionals alike. In addition, Digital-S promises to satisfy all such requirements at a significant new level of economy, unknown to digital videotape recording before now. Finally, the Digital S compressed digital video interface offers a much needed method of transferring compressed digital S video signals between VCR’s and other video equipment without the need to decode and encode between non-compressed digital video formats.